”Vivado HLS 2019.2 で普通に C ソースコードを書いて Sobel フィルタを実装する1”の続き。
前回は、ivado HLS 2019.2 で普通に C ソースコードを書いて Sobel フィルタを実装するためのソースコードとテストベンチを貼った。今回は、C シミュレーション、 C コードの合成、 C/RTL 協調シミュレーション、 Export RTL を行う。
C シミュレーションを行った。結果を示す。
sobel_filter_axis3/solution/csim/build ディレクトリを示す。

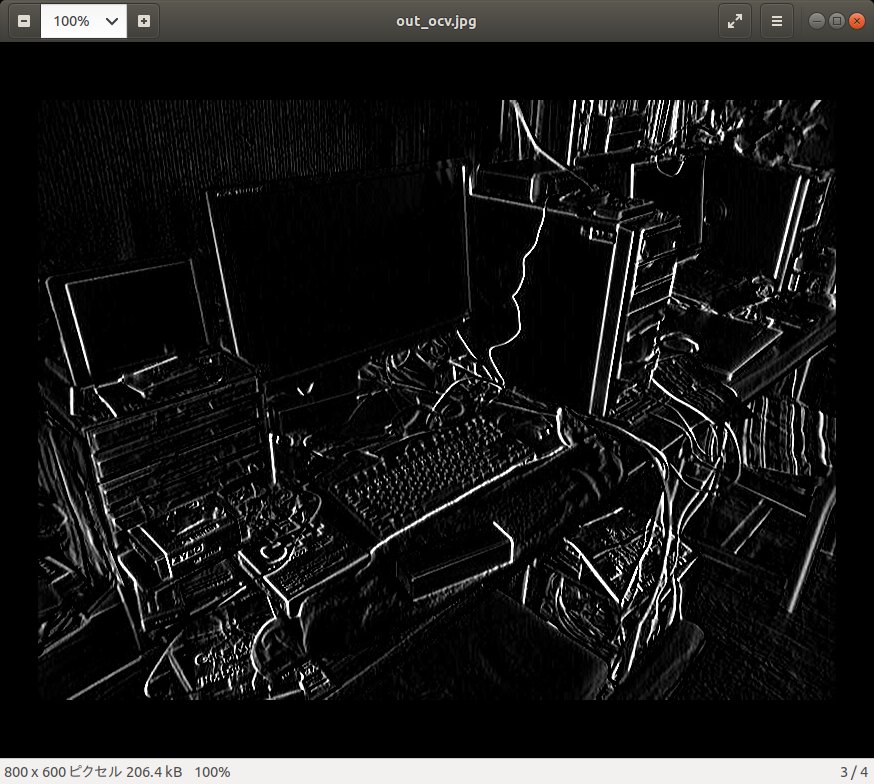
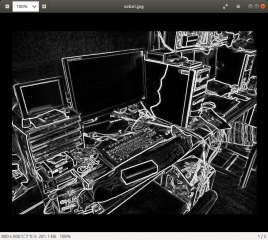
Sobel フィルタ処理結果の sobel.jpg を示す。綺麗なエッジが検出できている。
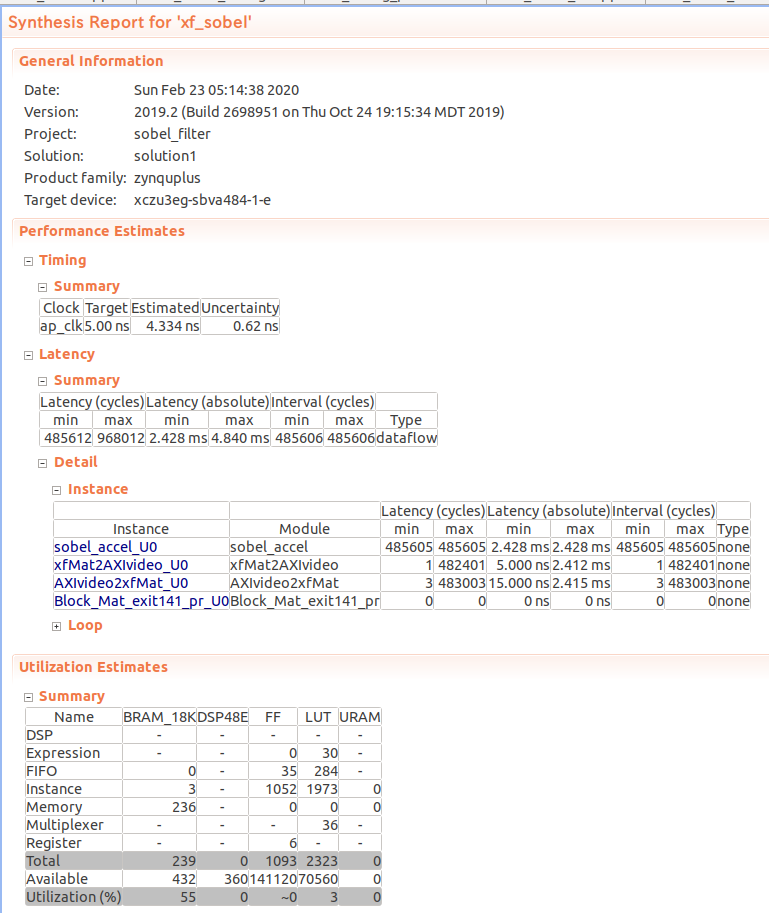
C コードの合成を行った。

Latency は 480016 クロックで、総ピクセル数よりも 16 クロック多いだけである。リソース使用量も少ない。
C/RTL 協調シミュレーションを行った。

Latency は 480041 クロックだった。優秀だ。
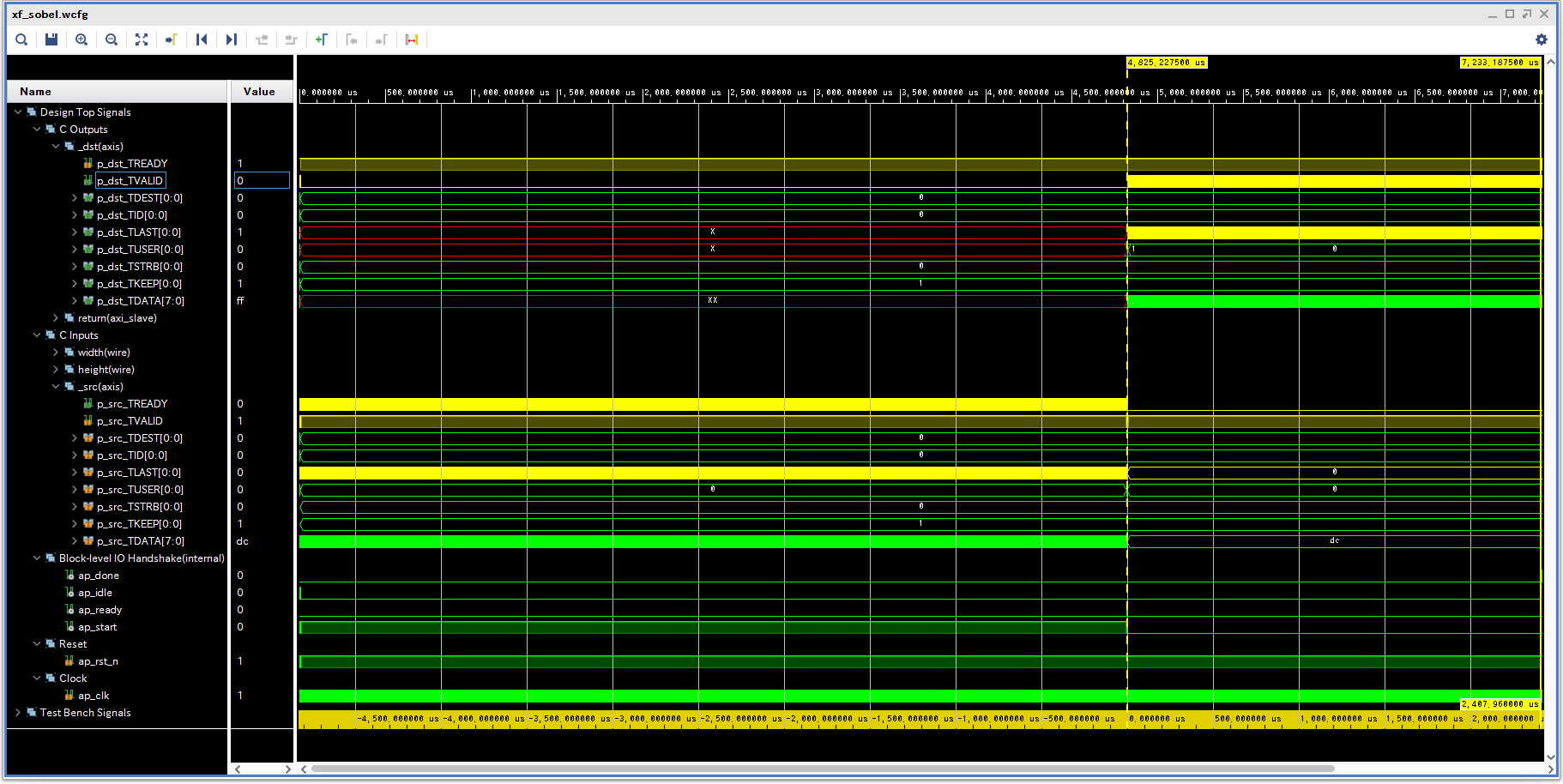
C/RTL 協調シミュレーションの波形を示す。

outs_TVALID も ins_TREADY もほとんど 1 にアサートされたままなので、スループットが高い。
最後に Export RTL を行った。結果を示す。

リソース使用量も少なく、 CP achieved post-implementation が 4.152 ns で大丈夫そうだ。
前回は、ivado HLS 2019.2 で普通に C ソースコードを書いて Sobel フィルタを実装するためのソースコードとテストベンチを貼った。今回は、C シミュレーション、 C コードの合成、 C/RTL 協調シミュレーション、 Export RTL を行う。
C シミュレーションを行った。結果を示す。

sobel_filter_axis3/solution/csim/build ディレクトリを示す。

Sobel フィルタ処理結果の sobel.jpg を示す。綺麗なエッジが検出できている。

C コードの合成を行った。
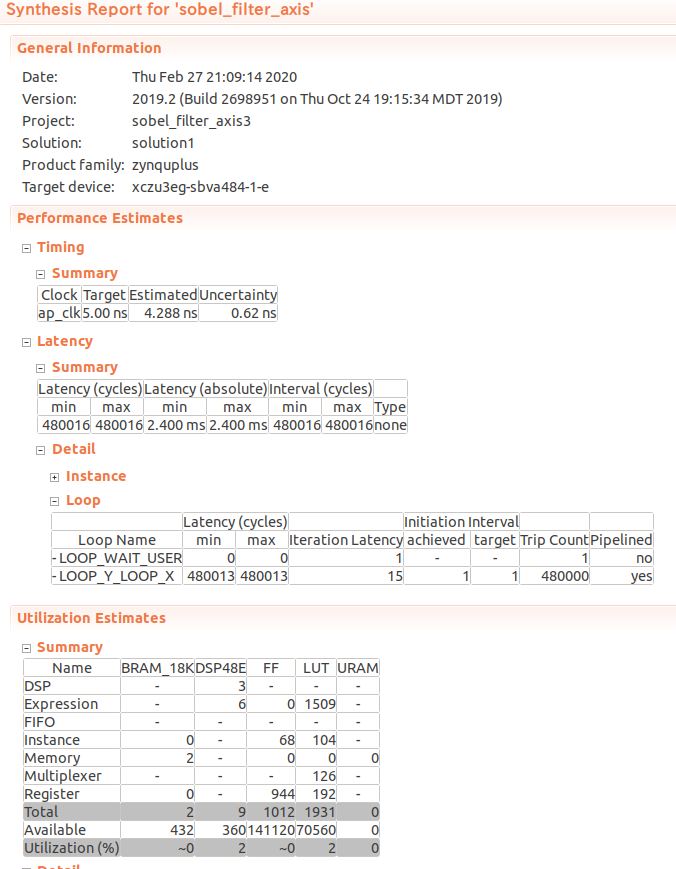
Latency は 480016 クロックで、総ピクセル数よりも 16 クロック多いだけである。リソース使用量も少ない。
C/RTL 協調シミュレーションを行った。

Latency は 480041 クロックだった。優秀だ。
C/RTL 協調シミュレーションの波形を示す。

outs_TVALID も ins_TREADY もほとんど 1 にアサートされたままなので、スループットが高い。
最後に Export RTL を行った。結果を示す。
リソース使用量も少なく、 CP achieved post-implementation が 4.152 ns で大丈夫そうだ。